Lab 6: Hypothesis testing#
Two sample t-test
ANOVA for multiple samples
F-test for equal variance
Association chi-square test
Nonparametric test (Mann-Whitney) for two samples
Likelihood ratio test
Normality test
Two sample t-test#
We first generate data in R. The observations in the control group are simulated from \(Normal(1,1)\). The treatment group is simulated from \(Normal(2,1)\).
control = rnorm(20, mean=1, sd=1)
treatment = rnorm(30, mean=2, sd=1)
boxplot(control, treatment, col=c("orange","brown"))

\(\mu_1\): the population mean of the control population
\(\mu_2\): the population mean of the treatment population
\(H_0: \mu_1 = \mu_2\) and \(H_1: \mu_1\ne \mu_2\)
We perform the two sample t-test in R. This is a two-sided test.
t.test(x=control, y=treatment, alternative="two.sided")
Welch Two Sample t-test
data: control and treatment
t = -6.1728, df = 47.484, p-value = 1.419e-07
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.7928967 -0.9116999
sample estimates:
mean of x mean of y
0.5820392 1.9343375
Because pvalue < 0.05, we reject the null and accept the alternative hypothesis that two population means (control and treatment) are not equal to each other.
Analysis of Variance (ANOVA)#
We generate multiple samples from the normal distributions with the same variance, and combine the samples as a data.frame in R. The first column is data and the second column denotes groups.
data = matrix(0,nrow=30,ncol=2)
data[1:12,1] = rnorm(12,mean=3,sd=1)
data[1:12,2]= 1
data[13:20,1] = rnorm(8,mean=3,sd=1)
data[13:20,2]= 2
data[21:30,1] = rnorm(10,mean=3,sd=1)
data[21:30,2] = 3
colnames(data) = c("bloodtest","group")
data = data.frame(data)
data$group = as.factor(data$group)
boxplot(data$bloodtest ~ data$group, col=c("orange","darkorange","brown"))

\(H_0: \mu_1=\mu_2=\mu_3\) and \(H_1\): at least two population means are not equal
We perform ANOVA in R.
fit = aov(data$bloodtest~data$group)
summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
data$group 2 0.362 0.1808 0.182 0.835
Residuals 27 26.854 0.9946
Because pvalue > 0.05, we cannot reject the null hypothesis. Next, we generate multiple samples from the normal distributions with different means.
data = matrix(0,nrow=30,ncol=2)
data[1:12,1] = rnorm(12,mean=3,sd=1)
data[1:12,2]= 1
data[13:20,1] = rnorm(8,mean=5,sd=1)
data[13:20,2]= 2
data[21:30,1] = rnorm(10,mean=3,sd=1)
data[21:30,2] = 3
colnames(data) = c("bloodtest","group")
data = data.frame(data)
data$group = as.factor(data$group)
boxplot(data$bloodtest ~ data$group, col=c("orange","darkorange","brown"))

We perform ANOVA in R.
fit = aov(data$bloodtest~data$group)
summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
data$group 2 40.09 20.05 16.84 1.79e-05 ***
Residuals 27 32.14 1.19
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
F-test to compare two variances#
We generate the control and treatment groups from two normal distributions with the same variance, and perform the F test to compare the two population variances.
\(H_0:\sigma_1^2 = \sigma_2^2\) and \(H_0:\sigma_1^2 \ne \sigma_2^2\)
control = rnorm(20, mean=1, sd=1)
treatment = rnorm(30, mean=2, sd=1)
boxplot(control, treatment, col=c("orange","brown"))
var.test(x=control, y=treatment, alternative = "two.sided")
F test to compare two variances
data: control and treatment
F = 0.92667, num df = 19, denom df = 29, p-value = 0.8801
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.415308 2.225798
sample estimates:
ratio of variances
0.9266658

Then, we generate the control and treatment groups from two normal distributions with unequal variances.
control = rnorm(20, mean=1, sd=5)
treatment = rnorm(30, mean=2, sd=1)
boxplot(control, treatment, col=c("orange","brown"))
var.test(x=control, y=treatment, alternative = "two.sided")
F test to compare two variances
data: control and treatment
F = 59.657, num df = 19, denom df = 29, p-value < 2.2e-16
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
26.73697 143.29387
sample estimates:
ratio of variances
59.65749
Association chi-square test#
A contingency table is generated from an R build-in dataset survey using an R function table().
library(MASS) # load the MASS package
tbl = table(survey$Smoke, survey$Exer)
tbl #the contingency table
Freq None Some
Heavy 7 1 3
Never 87 18 84
Occas 12 3 4
Regul 9 1 7
\(H_0\): smoking and exercise are independent and \(H_1\): not independent
We perform the chi-square test to test if smoking is associated with exercise.
chisq.test(tbl)
Warning message in chisq.test(tbl):
“Chi-squared approximation may be incorrect”
Pearson's Chi-squared test
data: tbl
X-squared = 5.4885, df = 6, p-value = 0.4828
Nonparametric test (Mann-Whitney) for two samples#
Because two sample t-test assumes that data follow the normal distribution. If the normality assumption is not satisfied, it is not appropriate to use two sample t-test. But we may use nonparametric tests, because nonparametric tests do not assume underlying probability distributions. In this example, we generate two samples from the exponential distributions with different means. Let \(\mu_1\) and \(\mu_2\) be two population means. In this case, \(\mu_1=1/2\) and \(\mu_2=1/5\).
\(H_0: pop_1=pop_2\) and \(H_1:pop_1\ne pop_2\)
control = rexp(20, rate=2)
treatment = rexp(30, rate=5)
boxplot(control, treatment, col=c("orange","brown"))
We perform the nonparametric test
wilcox.test(control,treatment)
Wilcoxon rank sum exact test
data: control and treatment
W = 457, p-value = 0.001507
alternative hypothesis: true location shift is not equal to 0
If the sample size is small (<5), it is not appropriate to use two sample t-test to compare two samples. But we can use nonparametric tests to compare two samples with a small sample size.
Likelihood Ratio Test (LRT)#
x = rnorm(20, mean=1.5, sd = 1)
\(H_0: \mu = 1\) and \(H_1:\mu\ne 1\)
We assume that the variance \(\sigma^2=1\) is given and calculate the loglikelihood score log_L0 for the null hypothesis \(\mu=1\)
log_L0 = sum(log(dnorm(x,mean=1,sd=1)))
We calculate the loglikelihood score log_L1 for the alternative hypothesis. Because the alternative hypothesis does not specify the value of \(\mu\), we use the maximum likelihood estimate (i.e., the sample average) of \(\mu\) to calculate the loglikelihood score.
mu_hat = mean(x)
log_L1 = sum(log(dnorm(x,mean=mu_hat,sd=1)))
We calculate the LRT statistic and find the pvalue
t = -2*(log_L0 - log_L1)
critical_value = qchisq(0.95,df=1)
pvalue = 1-pchisq(t,df=1)
print(paste("pvalue =",pvalue))
[1] "pvalue = 0.00269938387152102"
Normality test (Sapiro-Wilk test)#
Sapiro-Wilk test can be used to test if the real data follow the normal distribution or not. We simulate data from the exponential distribution with rate = 1.
data = rexp(100)
\(H_0:\) the normal distribution and \(H_1:\) not the normal distribution
The Q-Q plot can illustrate if the dataset follows the normal distribution. It is a scatter plot of the sample quantiles generated from data versus the quantiles expected from the normal distribution. If the dataset follows the normal distribution, the points should be close to the straight line.
par(mfrow=c(2,2))
hist(data,col="brown")
plot(density(data),col="brown")
qqnorm(data, pch=16)
qqline(data, col = "brown")
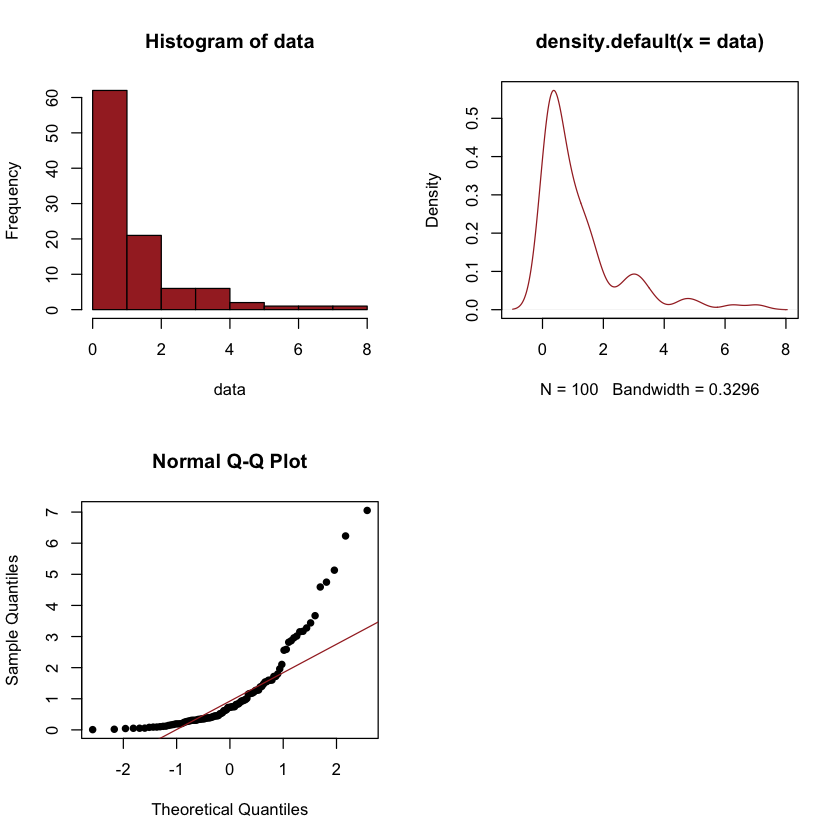
The Sapiro-Wilk test is widely used to check normality.
shapiro.test(data)
Shapiro-Wilk normality test
data: data
W = 0.75849, p-value = 1.58e-11