Lab 11: Bootstrap#
Suppose \(x_1, \ldots, x_{10} \sim \operatorname{Normal}\left(\mu, \sigma^2\right)\). Let \(\hat{\mu}\) be an estimator of \(\mu\). It could be the sample mean, sample median, maximum likelihood estimator, or any point estimator. We will calculate \(\operatorname{var}(\hat{\mu})\) using bootstrap samples.
data = rnorm(10, mean=4, sd=2)
sample_median = median(data)
sample_median
Parametric bootstrap:#
We estimate the unknown parameters, \(\hat{\mu}_{MLE}=\bar{x}\) and \(\widehat{\sigma^2}_{MLE}=\) sample variance
mu_hat = mean(data)
var_hat = var(data)
Generate \(k\) bootstrap samples from the \(Normal(\hat{\mu}_{MLE}, \widehat{\sigma^2}_{MLE})\)
k=100
bootstrap_sample = matrix(0, nrow=10, ncol=k)
for(i in 1:k){
bootstrap_sample[,i] = rnorm(10, mean=mu_hat, sd=sqrt(var_hat))
}
Calculate \(\hat{\mu}\), i.e., the sample median for each bootstrap sample, \(\left\{\widehat{\mu_1}, \ldots, \widehat{\mu_k}\right\}\)
sample_median = 1:k
for(i in 1:k){
sample_median[i] = median(bootstrap_sample[,i])
}
sample_median
- 4.44561786211302
- 4.67772682829274
- 3.95971029518667
- 3.56429335057606
- 3.22791076964354
- 4.15631415003103
- 3.55784257266926
- 3.90550150781958
- 3.09007472701129
- 4.91897524350442
- 4.32535237723643
- 4.83223639815947
- 4.46929668959023
- 3.69511283713728
- 2.68855557754801
- 2.85140838060864
- 3.03506042277317
- 4.20334173000931
- 3.95512806553804
- 2.65923691897263
- 3.02682707800827
- 3.59143334776439
- 2.38390048928055
- 4.32231456459515
- 4.27343965067856
- 2.82692356258043
- 3.65473106342307
- 3.73188321927561
- 3.42709245173773
- 4.10427914767153
- 4.77495513029408
- 3.90674431199055
- 3.35159200455574
- 3.64528696398739
- 3.59144224138914
- 3.07424947805679
- 4.30598955667739
- 5.00962542529426
- 3.34764937395769
- 4.84854483747192
- 4.00925426768146
- 3.65788344395059
- 3.84512184008322
- 3.53713712767478
- 3.92167018089209
- 4.09844644374319
- 4.1038718403586
- 4.84581570094966
- 3.73743228530132
- 3.16548900622553
- 4.64148149593731
- 4.26678621069261
- 4.29102920733568
- 3.62127507443068
- 4.51414046741928
- 3.84800778802832
- 4.06587792244641
- 3.76486361672103
- 6.09200255403587
- 4.54743151520859
- 4.16831492675626
- 5.07621692973946
- 3.11781527924284
- 3.95615444325829
- 3.74621514553175
- 2.28505367529484
- 3.48134342791253
- 4.13755312369523
- 3.82767134390163
- 4.45827013923297
- 3.07662842476346
- 4.32525384294122
- 3.8522838159386
- 3.91783324019871
- 3.52846183603836
- 4.20205670992562
- 6.24415787739707
- 4.64662440415347
- 5.56005877102173
- 5.03235312377744
- 4.26968603062587
- 3.98168382038422
- 4.35175979853733
- 3.81066799440101
- 4.8246774926414
- 4.05818113591943
- 1.8942930720193
- 3.82179482277564
- 2.98054417735195
- 3.92967338842795
- 3.78697098031984
- 2.10136549471903
- 3.90641814272161
- 2.79860689429251
- 2.99086868777596
- 4.5347050847945
- 4.58846317460145
- 5.29011608139473
- 3.62915624213097
- 3.75564981709219
Calculate the sample variance \(S^2\) of \(\left\{\widehat{\mu_1}, \ldots, \widehat{\mu_k}\right\}\), i.e., \(\frac{1}{k-1} \sum_{i=1}^k\left(\widehat{\mu_i}-\widehat{\mu}\right)^2\) and \(\operatorname{var}(\hat{\mu}) \approx S^2\)
var(sample_median)
Nonparametric bootstrap#
We generate bootstrap samples by resampling the original data with replacement.
bootstrap_sample = matrix(0, nrow=10, ncol=k)
for(i in 1:k){
bootstrap_sample[,i] = sample(data,10,replace=T)
}
We calculate the sample median for each bootstrap sample
sample_median = 1:k
for(i in 1:k){
sample_median[i] = median(bootstrap_sample[,i])
}
sample_median
- 4.00634354968367
- 3.63888684062208
- 4.19995026619835
- 4.00634354968367
- 4.39355698271303
- 2.32418829962678
- 3.16526592465523
- 4.19995026619835
- 5.49068418836301
- 3.2714301315605
- 2.79780921559364
- 3.63888684062208
- 3.08379133471808
- 2.71650192859014
- 3.2714301315605
- 3.2714301315605
- 2.16157372561978
- 3.16526592465523
- 4.00634354968367
- 3.2714301315605
- 4.00634354968367
- 3.2714301315605
- 2.71650192859014
- 2.32418829962678
- 3.16526592465523
- 4.00634354968367
- 2.79780921559364
- 3.16526592465523
- 4.39355698271303
- 3.2714301315605
- 2.16157372561978
- 3.63888684062208
- 3.63888684062208
- 3.16526592465523
- 2.79780921559364
- 4.92962076278674
- 3.2714301315605
- 6.58781139401298
- 5.49068418836301
- 6.58781139401298
- 2.32418829962678
- 4.00634354968367
- 2.32418829962678
- 5.49068418836301
- 3.63888684062208
- 4.00634354968367
- 3.16526592465523
- 2.71650192859014
- 6.58781139401298
- 2.79780921559364
- 3.63888684062208
- 3.2775653541664
- 4.19995026619835
- 5.29707747184833
- 3.63888684062208
- 2.79780921559364
- 5.49068418836301
- 4.00634354968367
- 6.58781139401298
- 2.32418829962678
- 3.2714301315605
- 6.58781139401298
- 3.16526592465523
- 4.00634354968367
- 5.49068418836301
- 2.24288101262328
- 3.63888684062208
- 5.49068418836301
- 2.24288101262328
- 4.39355698271303
- 3.63888684062208
- 4.39355698271303
- 3.63888684062208
- 4.19995026619835
- 4.00634354968367
- 4.39355698271303
- 2.32418829962678
- 3.2714301315605
- 6.58781139401298
- 2.24288101262328
- 3.63888684062208
- 3.63888684062208
- 3.3588726411699
- 6.58781139401298
- 3.16526592465523
- 5.49068418836301
- 4.39355698271303
- 2.24288101262328
- 3.63888684062208
- 6.58781139401298
- 4.92962076278674
- 4.19995026619835
- 2.79780921559364
- 5.03321138387595
- 3.83249355713676
- 3.63888684062208
- 2.32418829962678
- 3.2714301315605
- 6.69140201510219
- 5.49068418836301
We calculate the sample variance \(S^2\) of \(\left\{\widehat{\theta_1}, \ldots, \widehat{\theta_k}\right\}\), i.e., \(\frac{1}{k-1} \sum_{i=1}^k\left(\widehat{\theta_t}-\widehat{\theta}\right)^2\) and \(\operatorname{var}(\hat{\theta}) \approx S^2\)
var(sample_median)
Building bootstrap phylogenetic trees#
We build a distance phylogenetic tree using the DNA alignment in test.phy.
library(phybase)
data = read.dna.seq("./data/lab15_primates.phy",format="phylip")
seq = data$seq
d = dist.dna(seq)
rownames(d) = data$name
plot(nj(d))
Loading required package: ape
Loading required package: Matrix
Attaching package: ‘phybase’
The following objects are masked from ‘package:ape’:
dist.dna, node.height
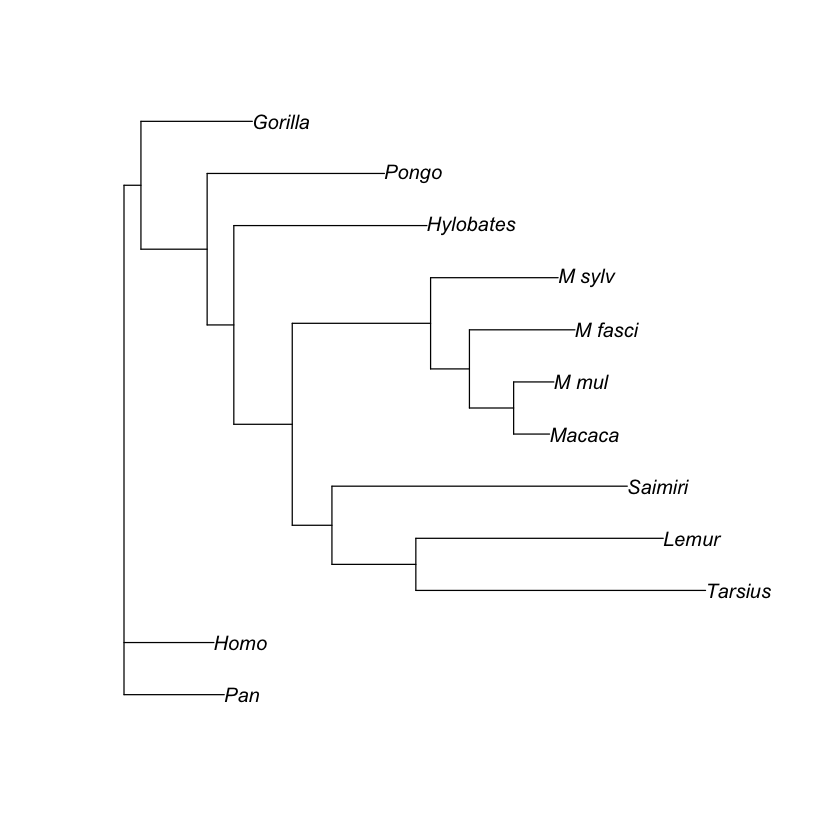
We generate 100 nonparametric boostrap samples, i.e., resampling columns of the DNA alignment with replacement. Then, we build a tree for each bootstrap sample.
ncol = dim(seq)[2]
nbootstrap = 100
bootstrap_tree = rep("",nbootstrap)
for(i in 1:nbootstrap){
columns = sample(1:ncol,ncol,replace=T)
bootstrap_sample = seq[,columns]
d = dist.dna(bootstrap_sample)
rownames(d) = data$name
bootstrap_tree[i] = write.tree(nj(d))
}
trees = read.tree(text=bootstrap_tree)
trees
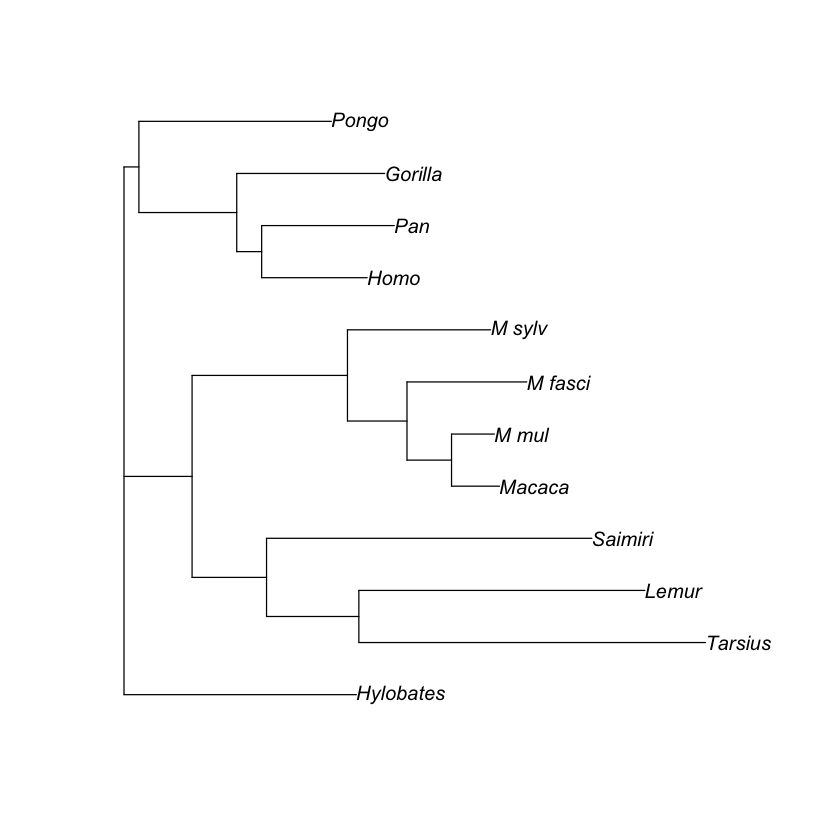
plot(trees[1])
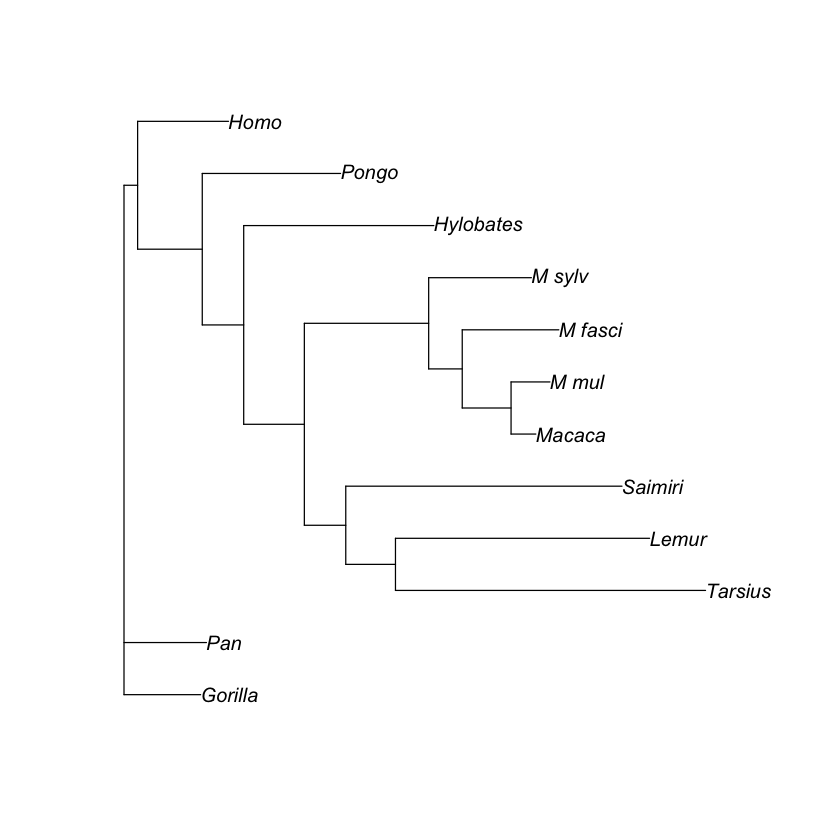
plot(trees[2])
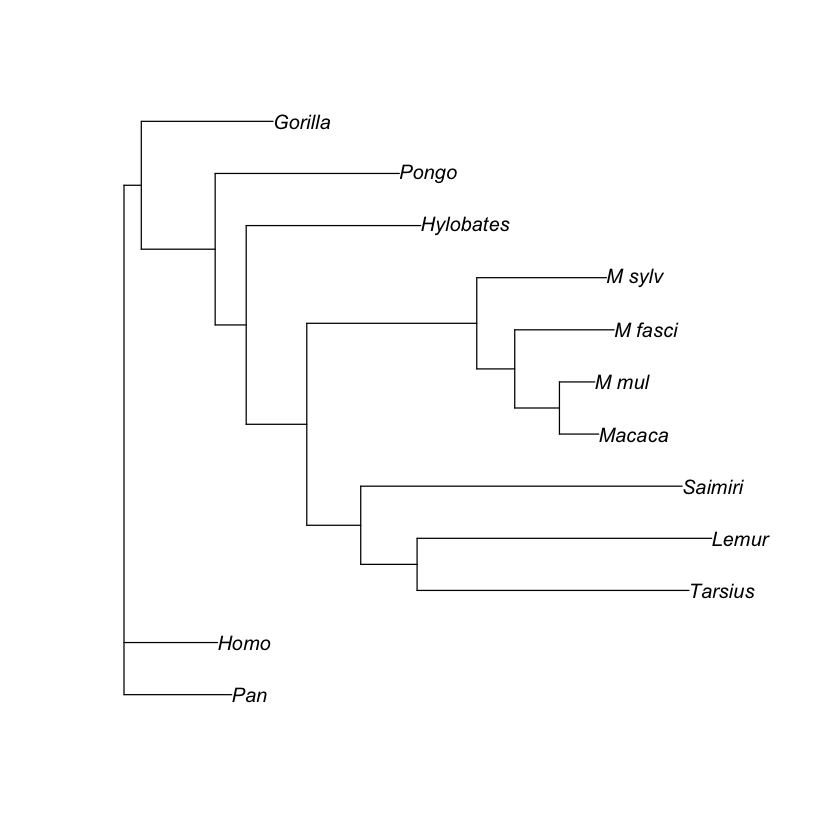
plot(trees[3])
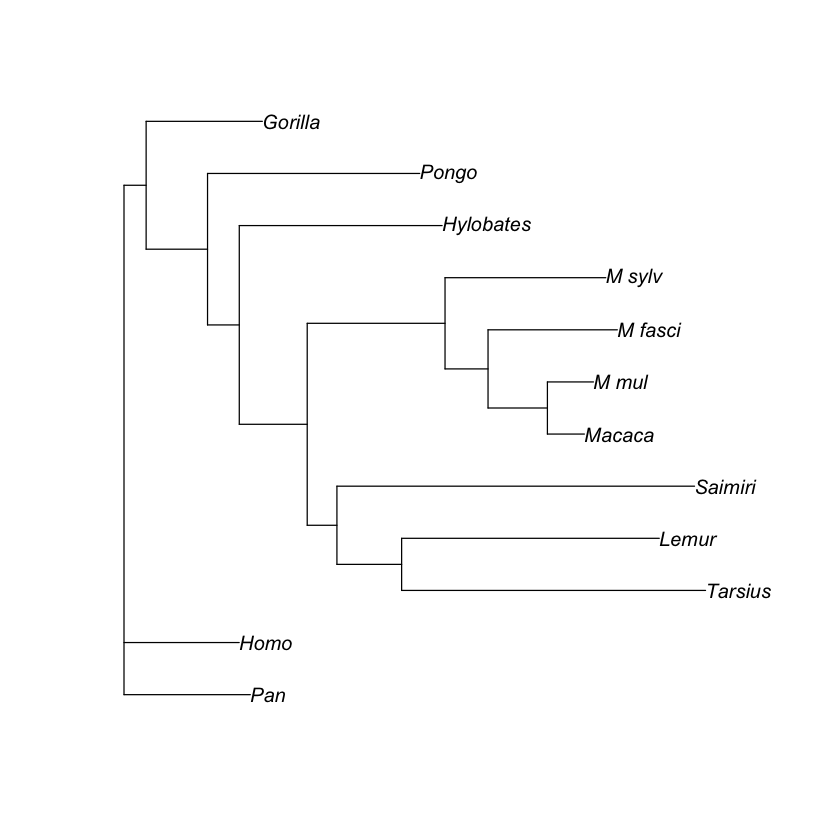
plot(trees[4])
100 phylogenetic trees